Amazon Athena
실습 소개
Athena를 이용하여 테이블 데이터를 조회할 수 있습니다.
실습 순서
S3 버킷에 source 폴더와 parquet 폴더에 데이터들이 쌓여 있고, 이에 대한 카달로그 정보는 Glue의 Data Catalog가 가지고 있습니다.
이제 Athena의 SQL 기능을 이용해서 S3에 있는 데이터를 쿼리하는 방법을 학습합니다.
-
Glue Crawler가 만든 parquet 테이블 을 선택하고 Action 버튼을 클릭하고, View data 를 클릭합니다.

-
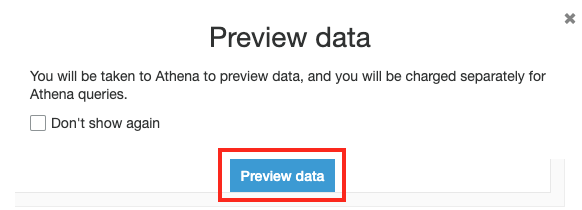
쿼리를 수행하기 위해서 Athena 서비스로 이동하게 됩니다. Preview Data 버튼을 선택합니다.
-
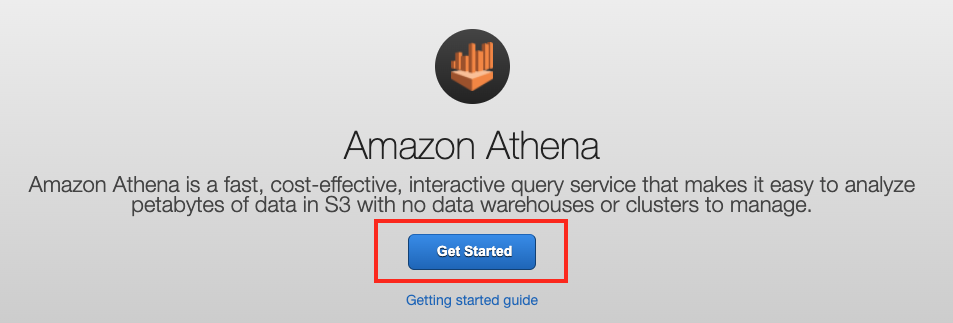
Athena 서비스로 이동하면, Get Started 버튼을 클릭 합니다. 한 번도 Athena를 실행할 적이 없을 경우에 이런 화면이 표시됩니다.
-
Database가
big-data-workshop이 선택되어져 있다면, 하단의 Tables의 parquet 테이블 우측의 점이 있는 부분을 클릭합니다. 그리고 Preview table을 선택합니다.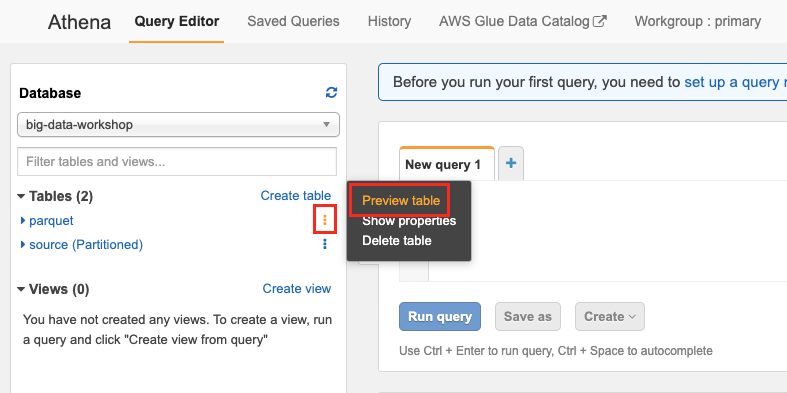
-
Athena를 처음 사용할 경우, 쿼리를 수행하기 전 쿼리 결과를 저장할 수 있도록 S3 위치를 지정해야 합니다. 따라서, 상단의 파란색 박스에 있는 set up a query result location in Amazon S3. 텍스트를 클릭합니다.
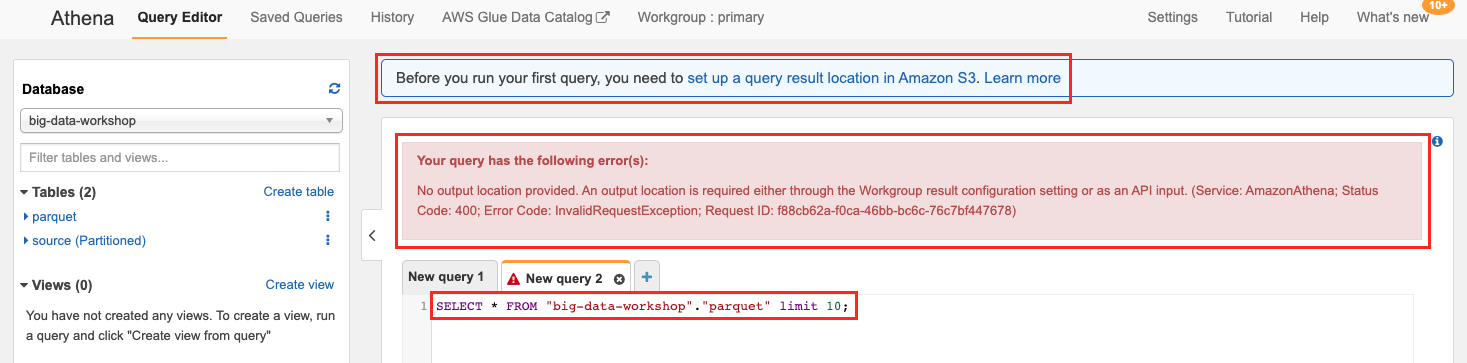
처음 Athena로 쿼리를 사용시 동작이 되지 않을 수 있습니다. 수행 결과를 S3에 써 놓고 이를 히스토리로 관리할 수 있습니다. 따라서 이럴 때는 아래와 같이 Athena 수행 후 로그를 남길 수 있는 S3 버킷과 Prefix를 적절히 제공합니다.
-
기존에 만들어진 S3 버킷 위치에 prefix를 넣어 저장할 위치를 지정합니다. 여기서는
s3://bigdata-workshop-[본인이메일id]/athena-log/처럼 설정합니다. 자동 완성 기능을 체크해 주고, 우측 하단의 Save 버튼을 클릭합니다.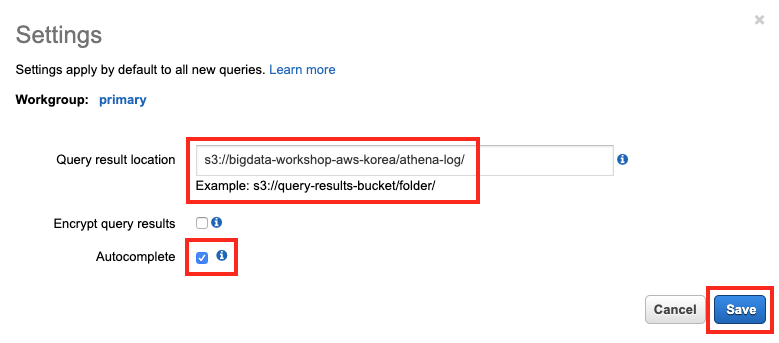
-
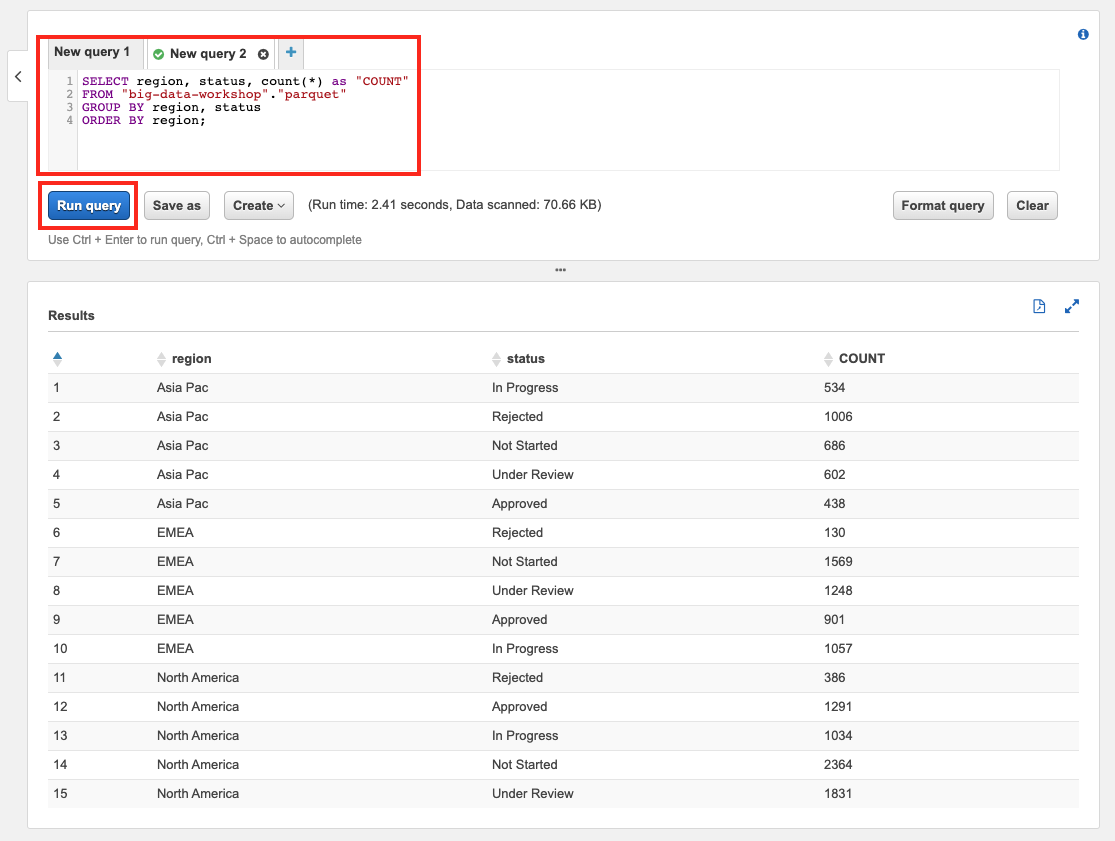
이제 Athena에서 SQL을 수행할 준비가 되었습니다. SQL을 입력 후, Run query 버튼을 클릭하여 쿼리를 수행합니다. 하단에 수행 결과를 볼 수 있습니다.
SELECT * FROM "big-data-workshop"."parquet" limit 10;
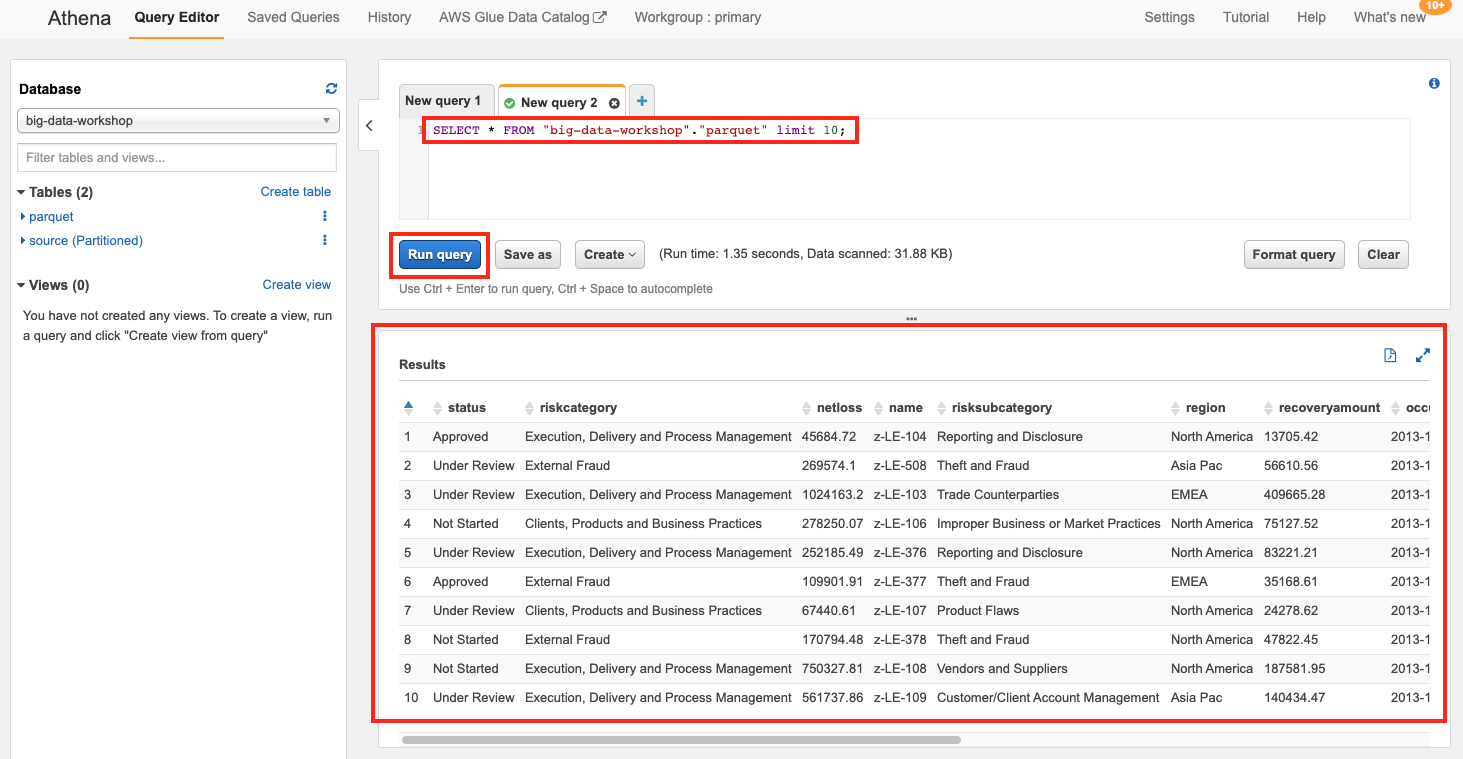
- 다음과 같이 ANSI 표준 SQL 문을 이용하여 S3내 데이터를 조회할 수 있습니다.
SELECT region, status, count(*) as "COUNT"
FROM "big-data-workshop"."parquet"
GROUP BY region, status
ORDER BY region;