AWS Glue
실습 소개
AWS Glue는 완전관리형 ETL(Extract, Transform, Load) 엔진입니다.
실습에서는 AWS Glue로 Kinesis Firehose가 S3에 저장한 데이터를 크롤링하여 Data Catalog를 만듭니다.
실습 순서
Glue ETL Job을 위한 Role 생성
-
AWS Glue에서 ETL Job을 수행하기 위해서는 특정 IAM Role 이 필요합니다. 따라서, IAM 서비스 에 접속합니다.
-
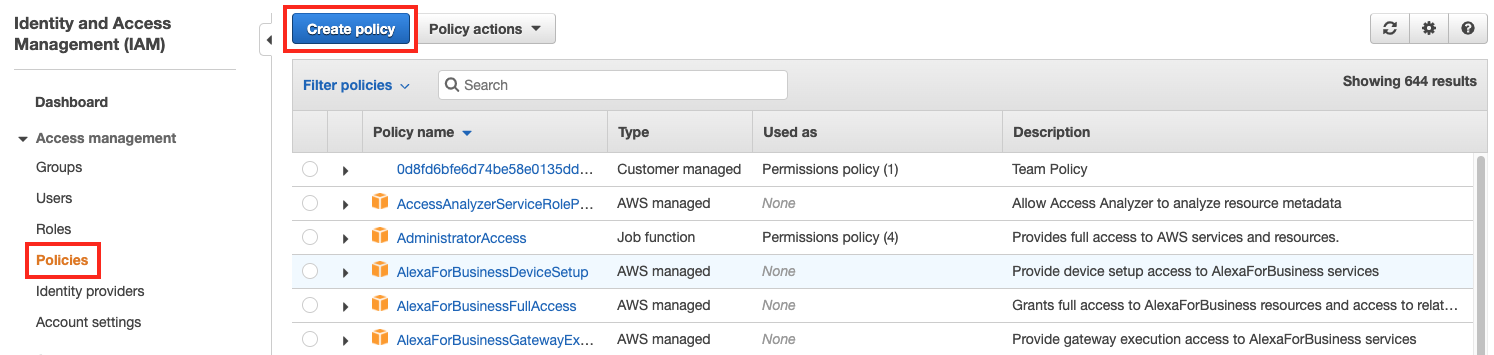
좌측 메뉴에서 Policies 를 클릭하고, 상단의 Create Policy 버튼을 클릭합니다.
-
Create Policy 화면에서 JSON 탭을 클릭하고 하단의 Policy 를 복사하여 붙여 넣고 Review Policy 버튼을 클릭합니다.
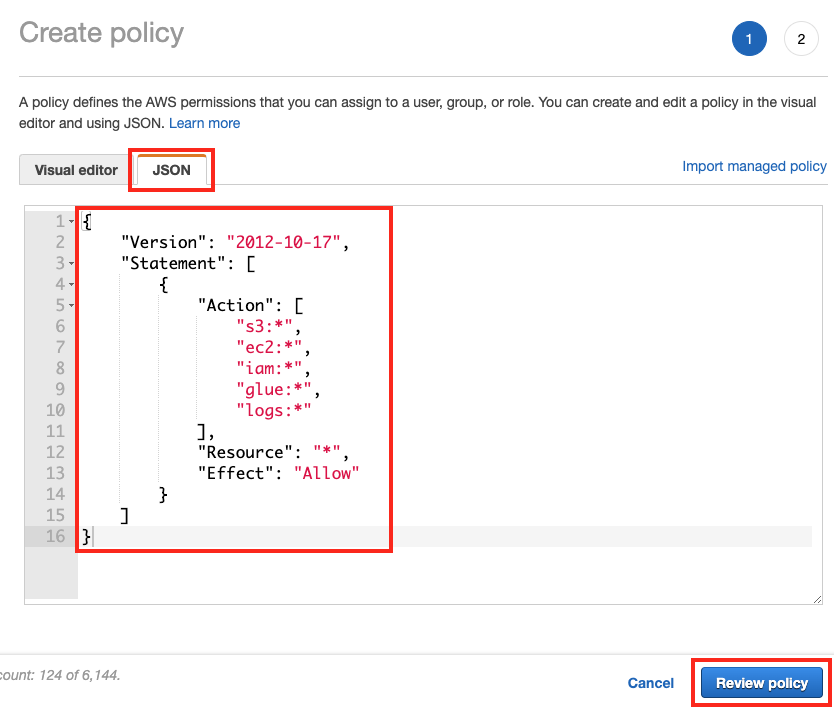
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:*",
"ec2:*",
"iam:*",
"glue:*",
"logs:*"
],
"Resource": "*",
"Effect": "Allow"
}
]
}
-
Review Policy 화면에서 Name은
BigDataGluePolicy를 입력하고 Create Policy 버튼을 클릭합니다.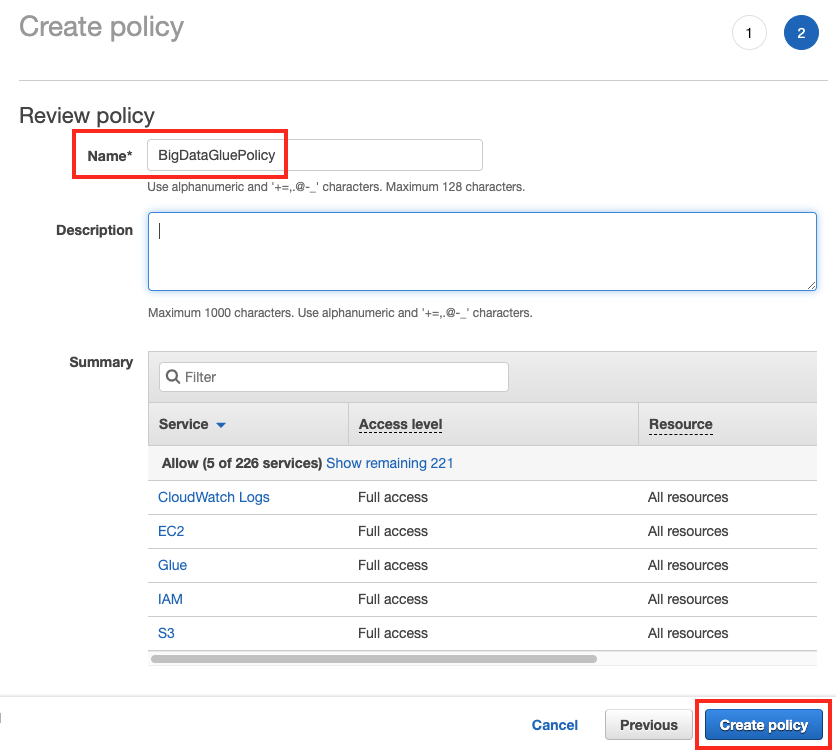
-
좌측 메뉴에서
Roles을 클릭하고 Create Role 버튼을 클릭합니다.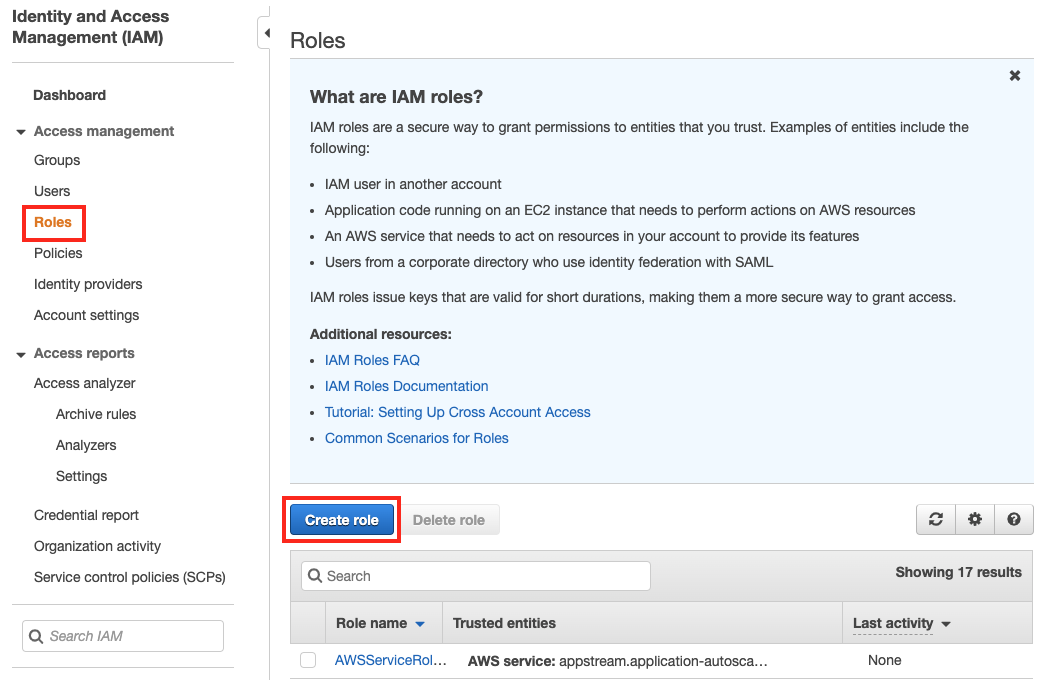
-
AWS service 박스에서 Or select a service to view its use cases 하단의 service 중 에서 Glue를 클릭하고 Next: Permission 버튼을 클릭합니다.
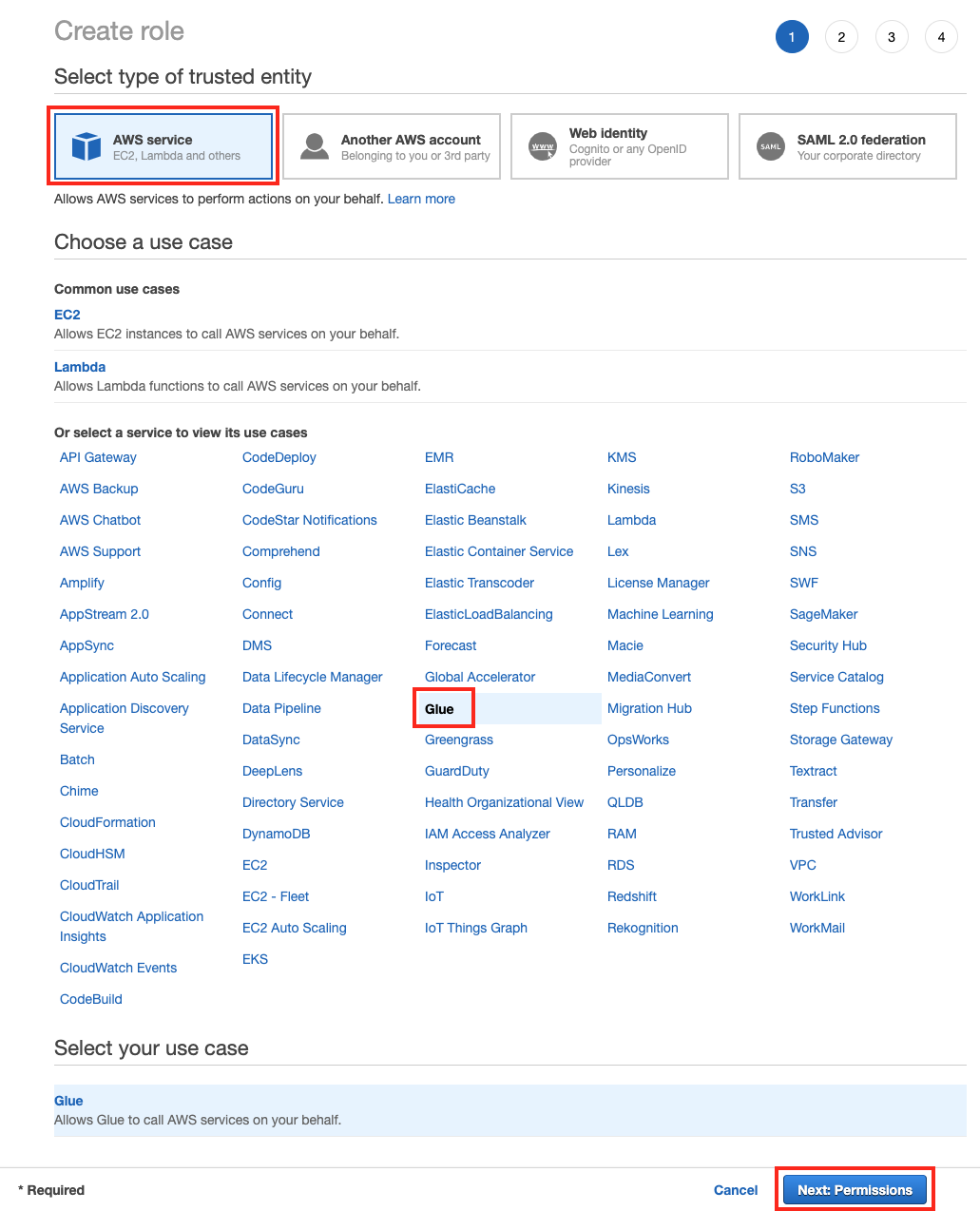
-
Search 입력창에 방금 만든
big를 입력하고BigDataGluePolicy를 선택하고 Next: Tags 버튼을 클릭합니다.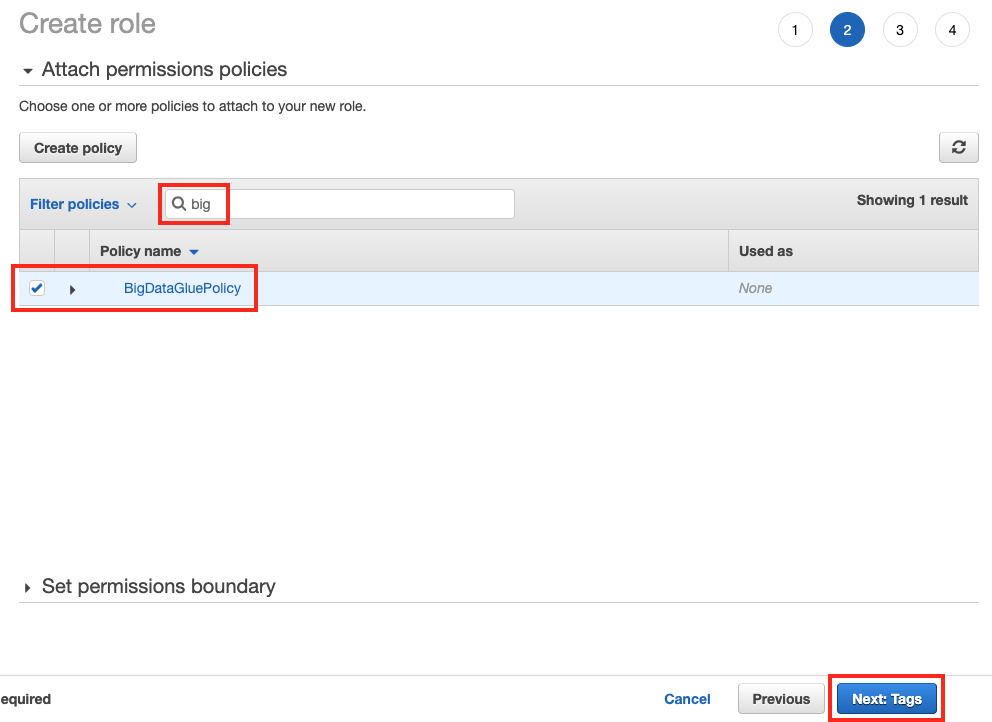
-
Tag의 Key에는
Name을 넣고, Value에big-data-lab을 넣은 후, Next: Review 버튼을 클릭합니다.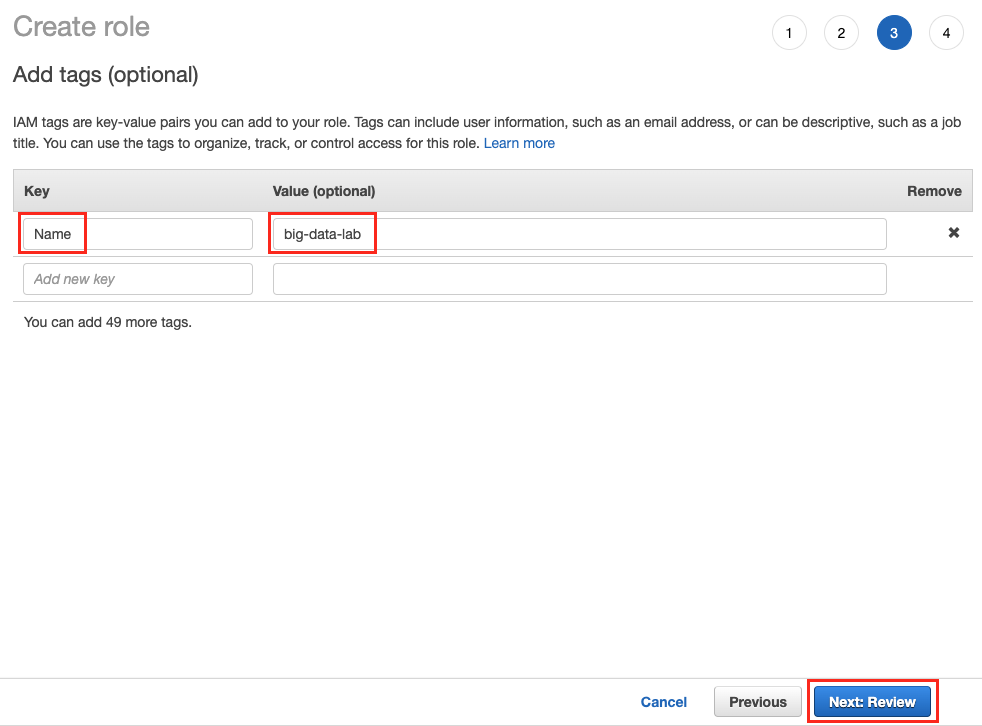
-
Review 화면에서 Role name은
BigDataGlueRole을 입력하고, 우측 하단의 Create Role 버튼을 클릭합니다.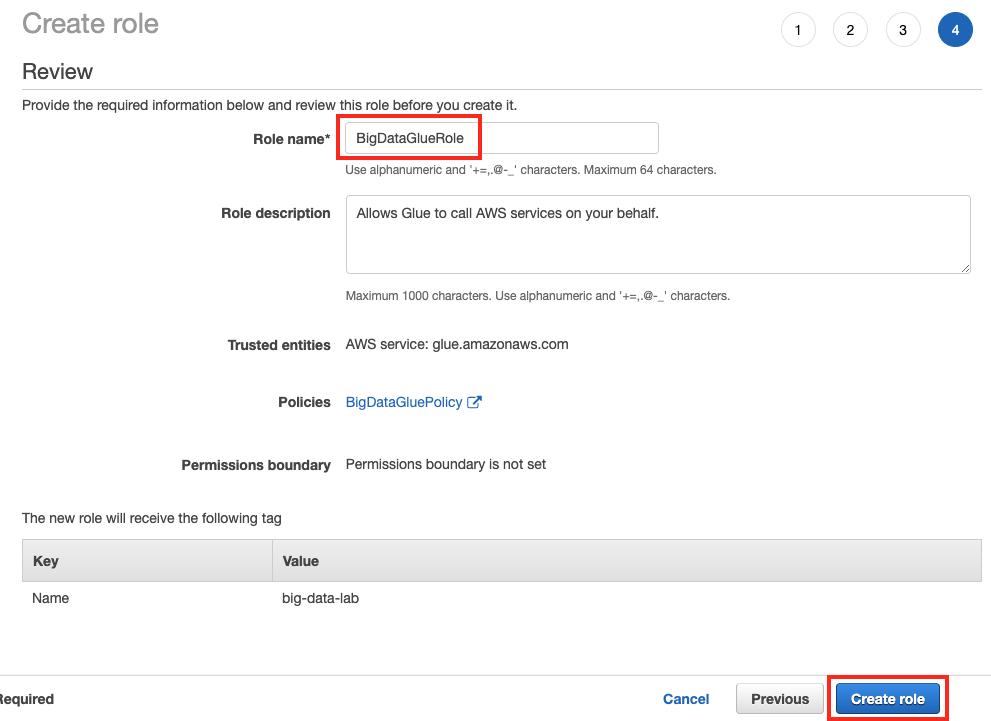
-
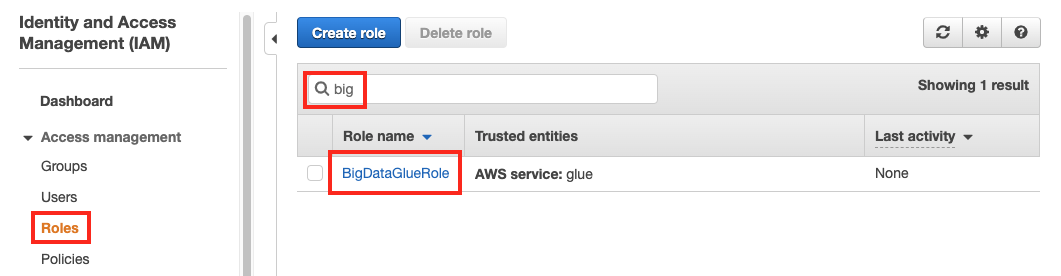
좌측 Roles 을 클릭하고, BigDataGlueRole 이 정상적으로 생성되었는지 확인합니다.
Glue Data Catalog 생성
S3에 저장된 데이터에 대한 Catalog를 만드는 작업을 합니다.
직접 수동으로 만들어 줄 수 있지만, Glue의 Crawler를 이용하면 자동으로 스키마 정보를 추출하여 Data Catalog를 생성할 수 있습니다.
-
AWS Management Console에서 AWS Glue 서비스로 이동합니다.
이전 Lab에서 생성한 S3내 source 폴더 아래 파일 들을 크롤링하여 테이블을 만들기 위하여 좌측 메뉴에서 Databases 를 클릭하고 Add database 버튼을 클릭합니다.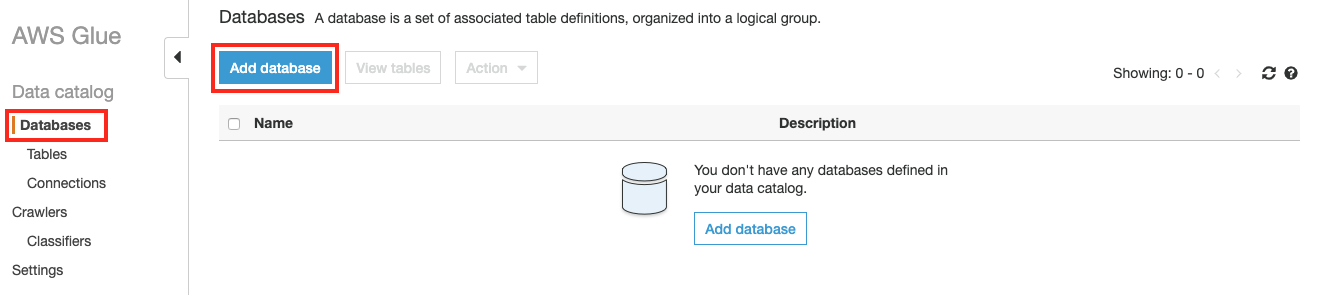
-
Database name 은
big-data-workshop을 입력하고 Create 버튼을 클릭합니다.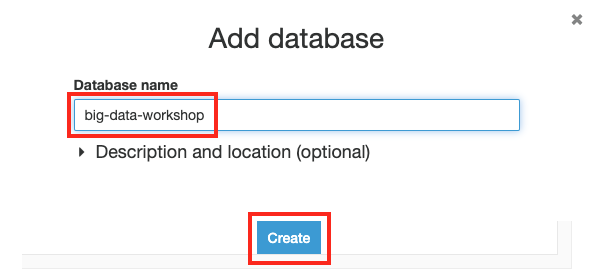
-
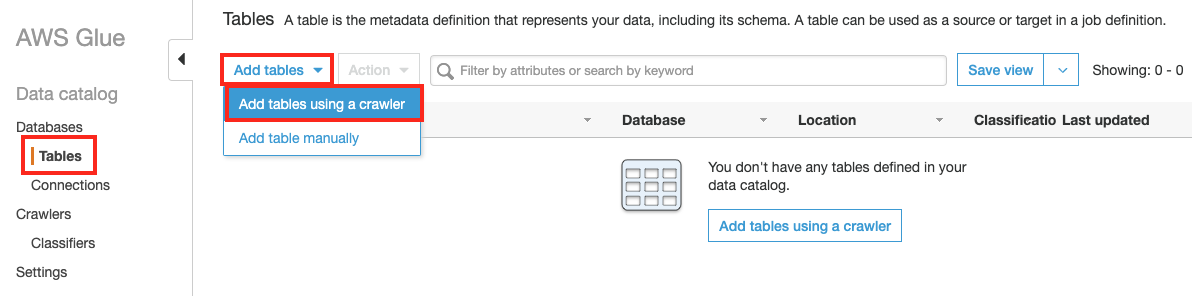
좌측 메뉴의 Tables 을 클릭하고 Add tables 버튼을 클릭한 후, Add tables using a crawler 를 클릭합니다.
-
Crawler info 에서 Crawler name에
big-data-crawler입력 후 Next 버튼을 클릭합니다.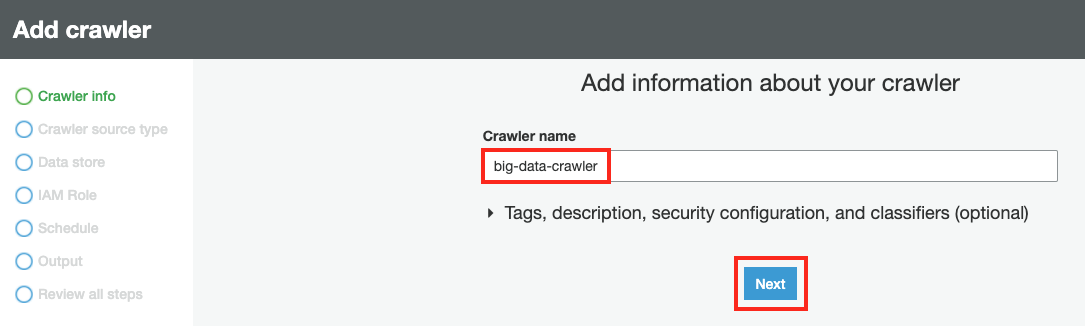
-
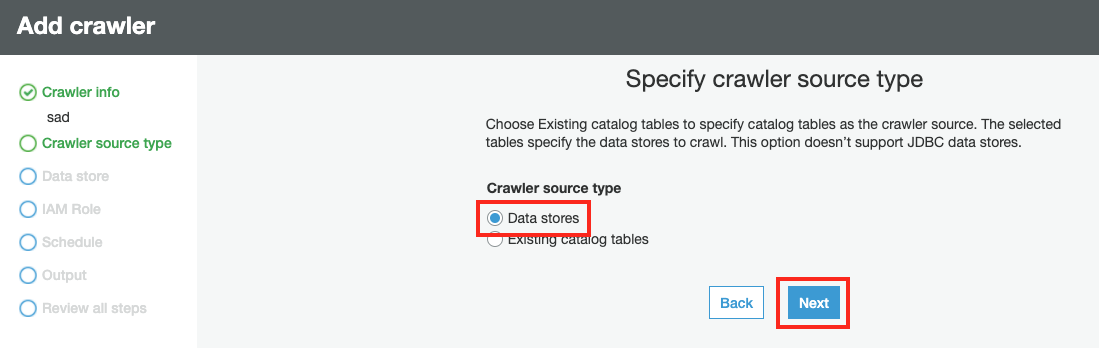
Crawler source type 에서 Cralwer source type 을 Data stores 를 선택하고 Next 버튼을 클릭합니다.
-
Data store 에서 Crawling 할 S3 버킷 및 폴더를 지정합니다. Include path 에
s3://bigdata-workshop-[본인이메일id]/source을 입력하거나, 탐색기 버튼을 클릭하여bigdata-workshop-[본인이메일id]버킷 아래 source 폴더를 선택 한 후 Next 버튼을 클릭합니다.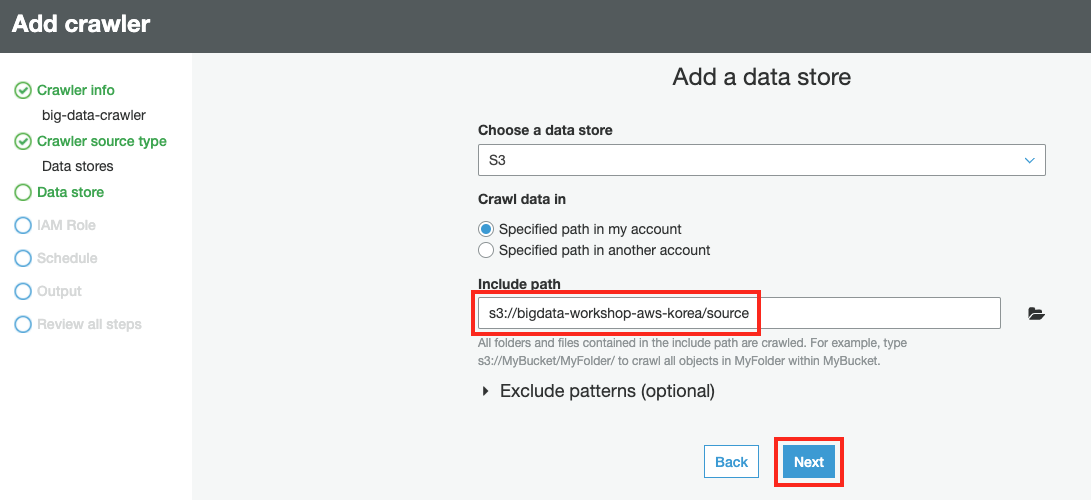
-
Add another data store는 No 를 선택하고 Next 버튼을 클릭합니다.
-
IAM Role 의 Choose an IAM role 에서 Choose an existing IAM role 을 선택하고 앞서 생성한
BigDataGlueRole을 선택한 후 Next 버튼을 클릭합니다.
-
Schedule 에서 Crawler는 on-demand 방식으로 수행할 수 있고, 배치 방식으로 수행할 수 있습니다. 실습에서는 on-demand 방식 으로 수행합니다.
Frequency를 Run on demand 를 선택하고 Next 버튼을 클릭합니다.
-
Output 에서 Database는 앞서 생성한
big-data-workshop를 선택한 후 Next 버튼을 클릭합니다.
-
Review all steps 에서 Crawler 설정을 모두 확인한 후 Finish 버튼을 클릭합니다.
-
Glue 좌측 메뉴의 Crawlers 에서 생성한 big-data-crawler 를 선택하고, Run crawler 버튼을 클릭합니다.
-
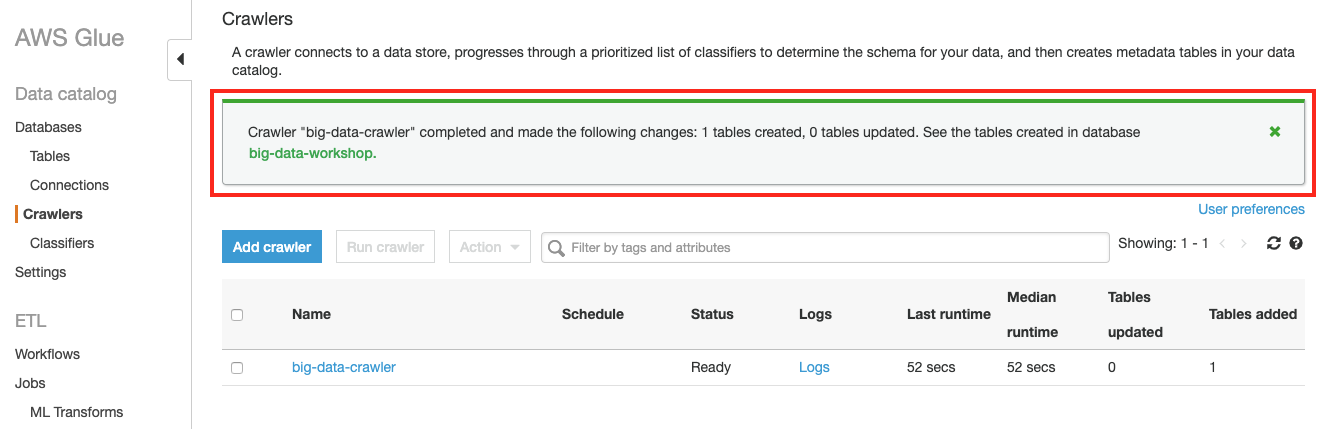
Crawler는 S3에 저장된 파일을 분석하고 테이블을 생성합니다. 크롤링이 끝난 후 테이블 1개( 테이블명: source )가 생성되었음을 확인합니다.
-
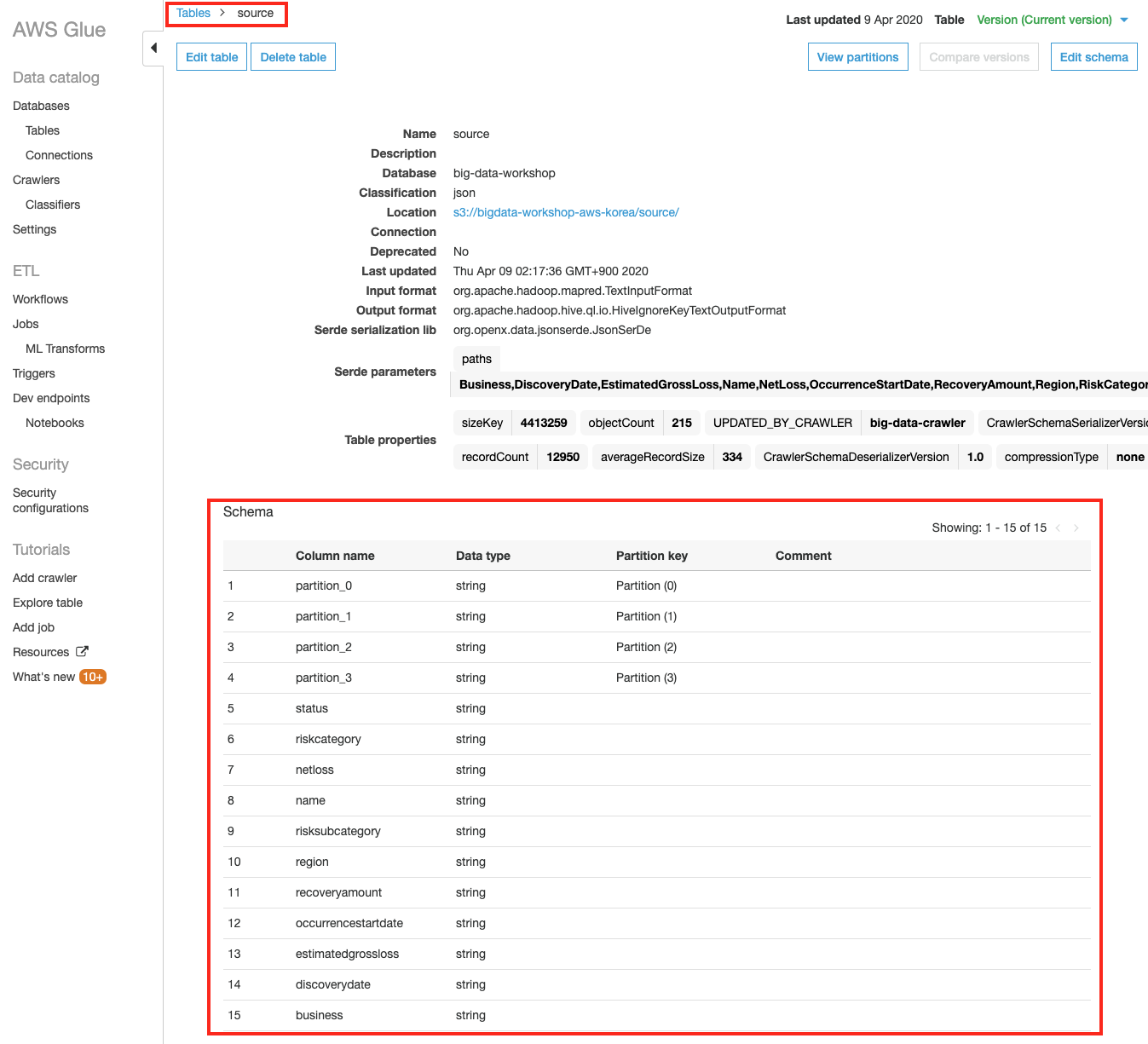
Glue 좌측 메뉴의 Tables 에서 방금 생성된 source 테이블 을 클릭하여 S3에 쌓인 데이터 기반으로 자동으로 추출된 source의 테이블 구조를 확인합니다.

Glue ETL Job 생성
Glue는 ETL Job을 생성하고 수행하는 기능을 가지고 있습니다.
따라서, Kinesis Firehose가 s3://bigdata-workshop-[본인이메일id]/source 에 저장한 JSON 파일 포맷 스트림 데이터를 Parquet 파일 포맷으로 변경할 수 있습니다.
일부 컬럼의 데이터 타입을 변경한 후 s3://bigdata-workshop-[본인이메일id]/parquet 폴더에 파일을 변환 저장하는 Glue ETL 작업을 생성해 보겠습니다.
-
우선 ETL후 결과 파일이 저장될 폴더를 생성합니다. S3 콘솔로 로그인한 후
bigdata-workshop-[본인이메일id]버킷를 선택하고parquet폴더를 생성합니다.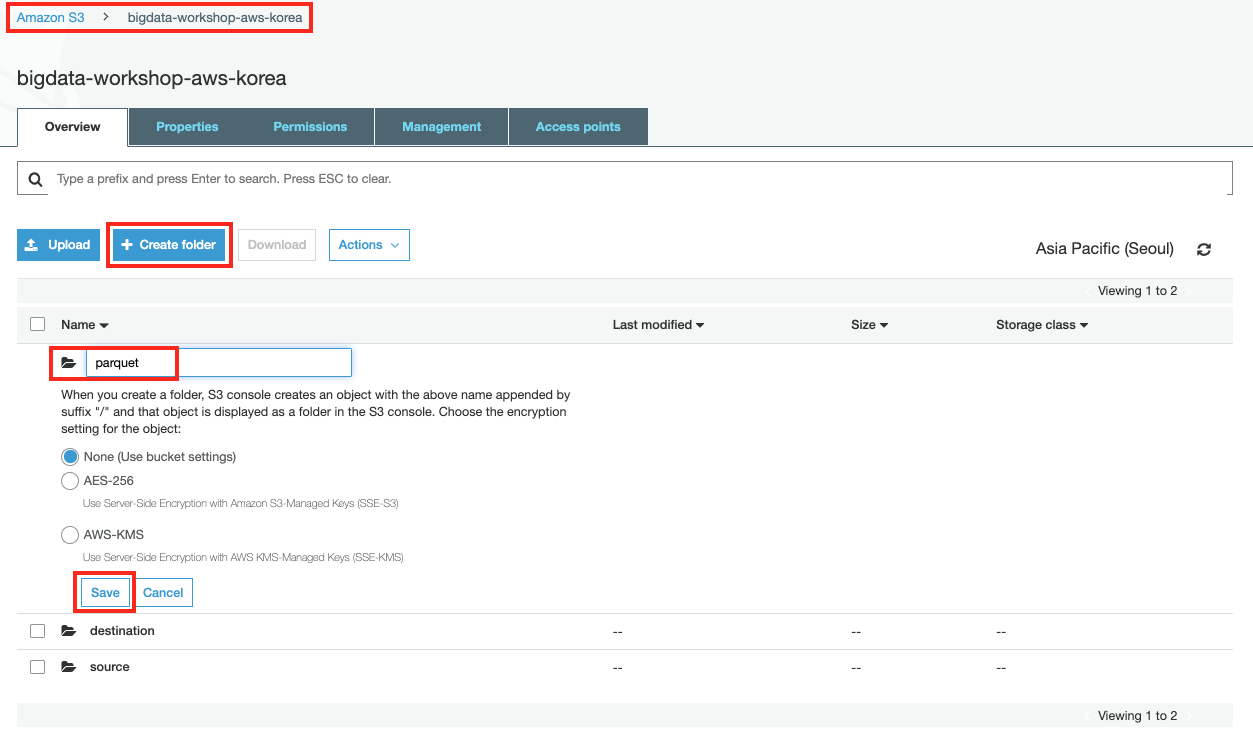
-
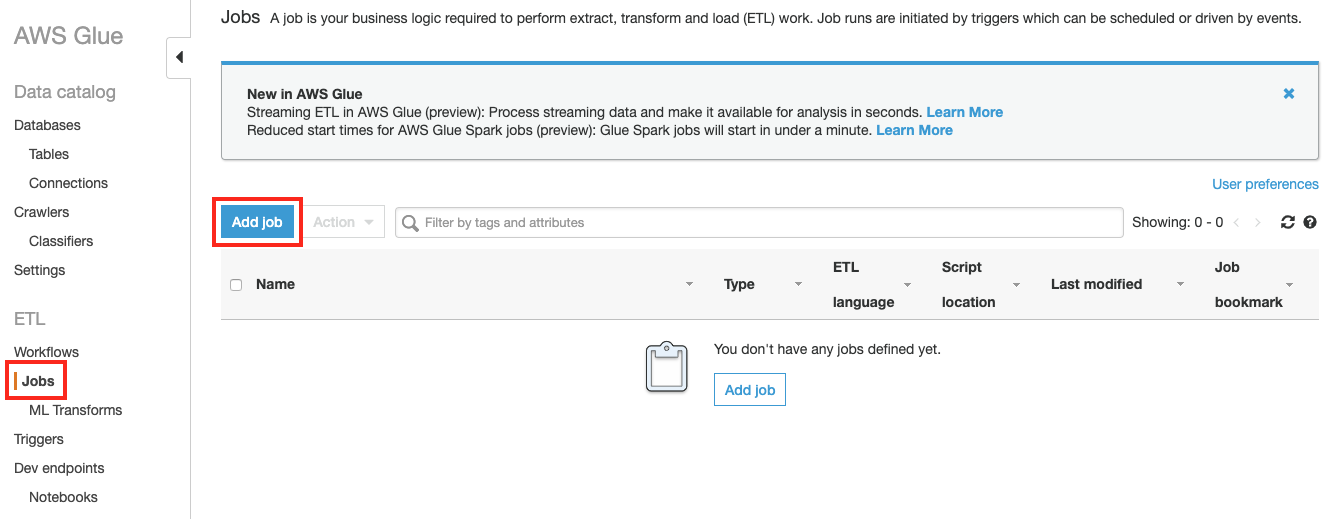
Glue 콘솔 에서 좌측 메뉴에서 Jobs 을 선택한 후 Add Job 버튼을 클릭합니다.
-
Job Properties 에서 Name은
JsonToParquet을 입력하고, IAM role은 앞서 생성한 BigDataGlueRole을 선택합니다. Advanced properties 에서 Job bookmark를 Enable 하여 Glue가 마지막으로 처리한 데이터를 기억하게 합니다. Next 를 클릭합니다.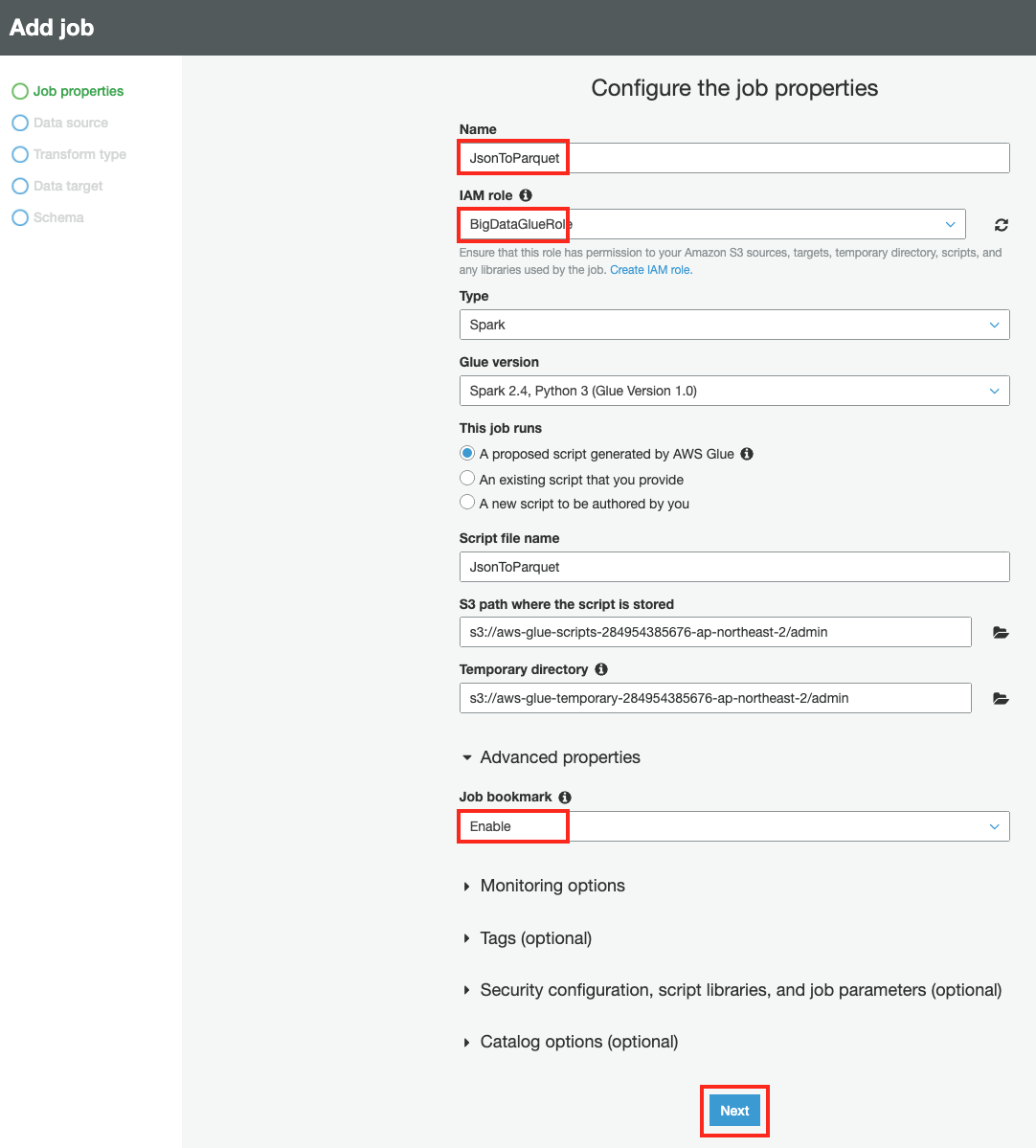
-
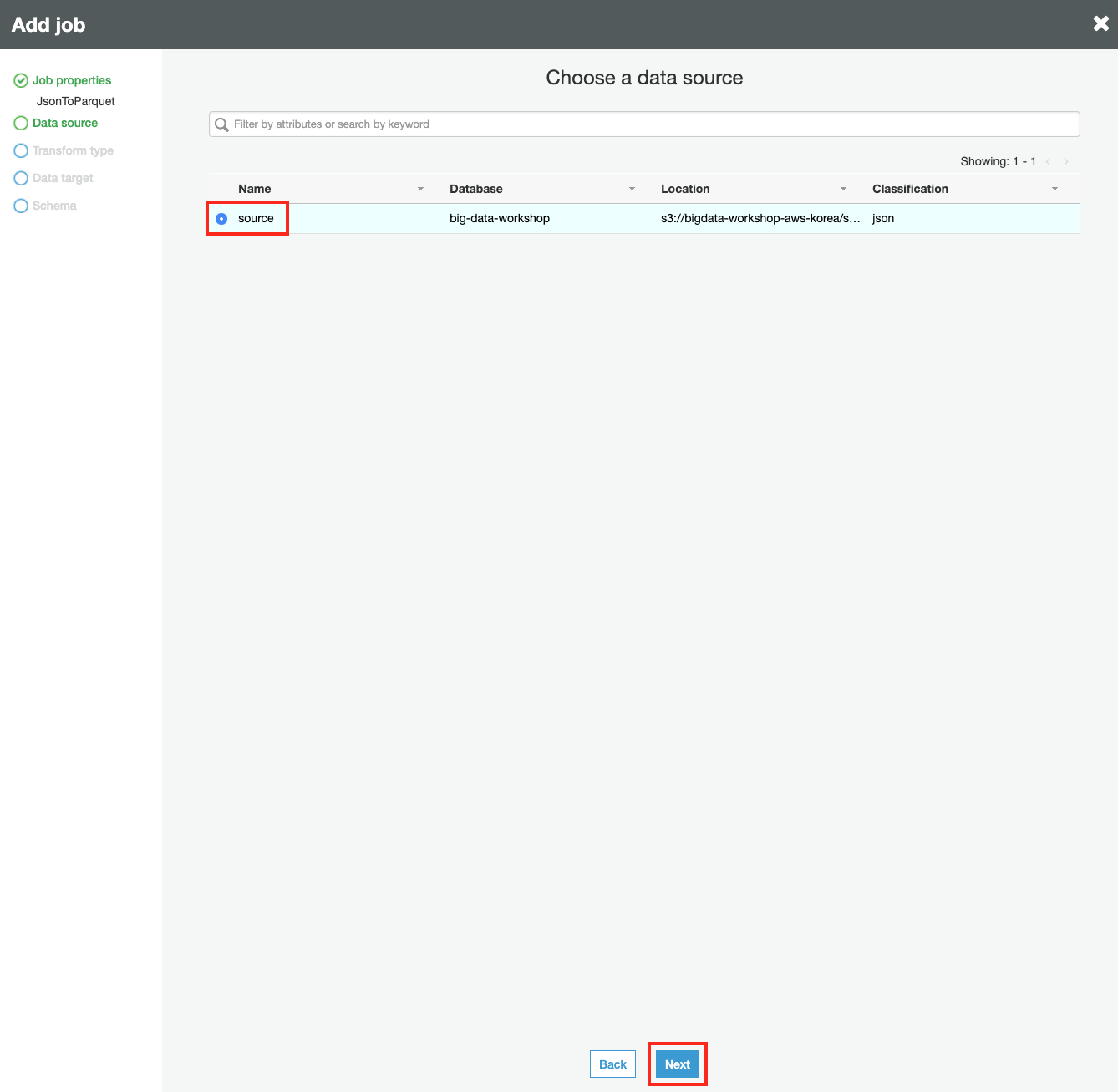
Data source 에서 source를 선택하고 Next 버튼을 클릭합니다.
-
Transform type 에서 Change schema 를 선택하고 Next 버튼을 클릭합니다.
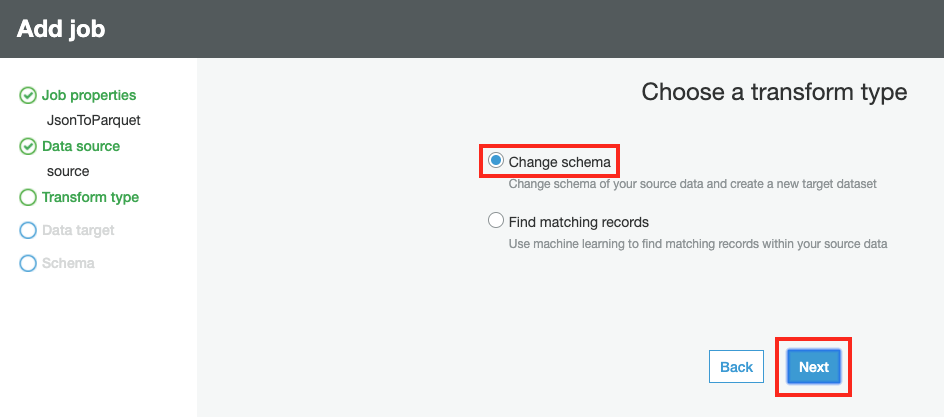
-
Data target 에서 Create tables in your data target 을 선택하고 Data store는 Amazon S3, Format은 Parquet, target bucket은
s3://bigdata-workshop-[본인이메일id]/parquet를 입력합니다. Next 버튼을 클릭합니다.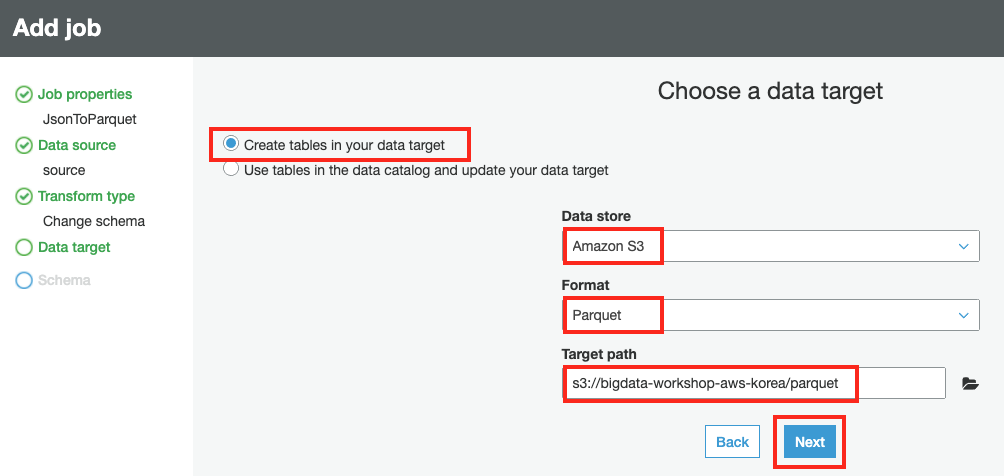
-
Map the source columns to target columns 에서 occurencestartdate, discoverydate 컬럼의 data type을 DATE 로 변경한 후, Save job and edit script 버튼을 클릭합니다.
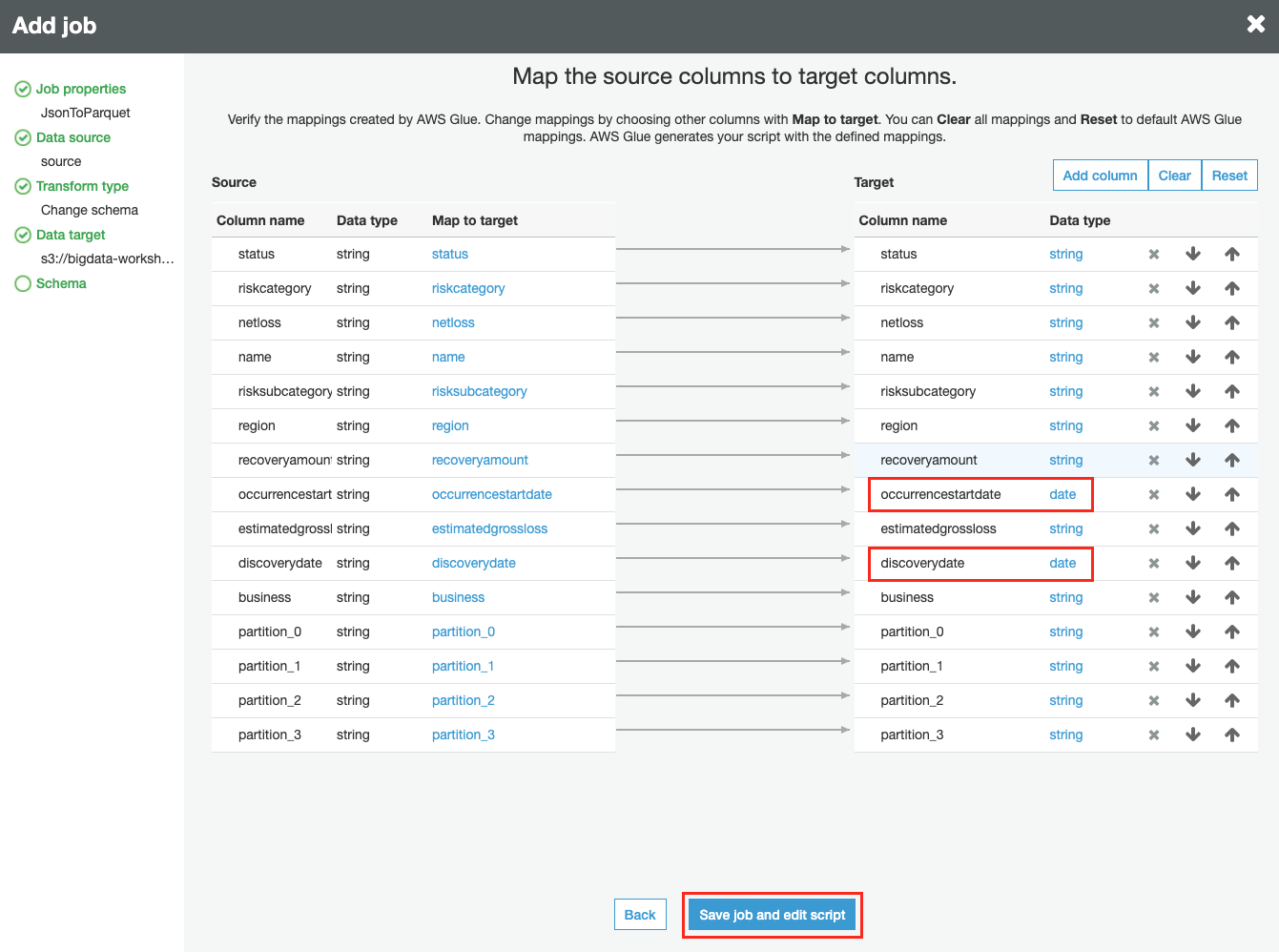
-
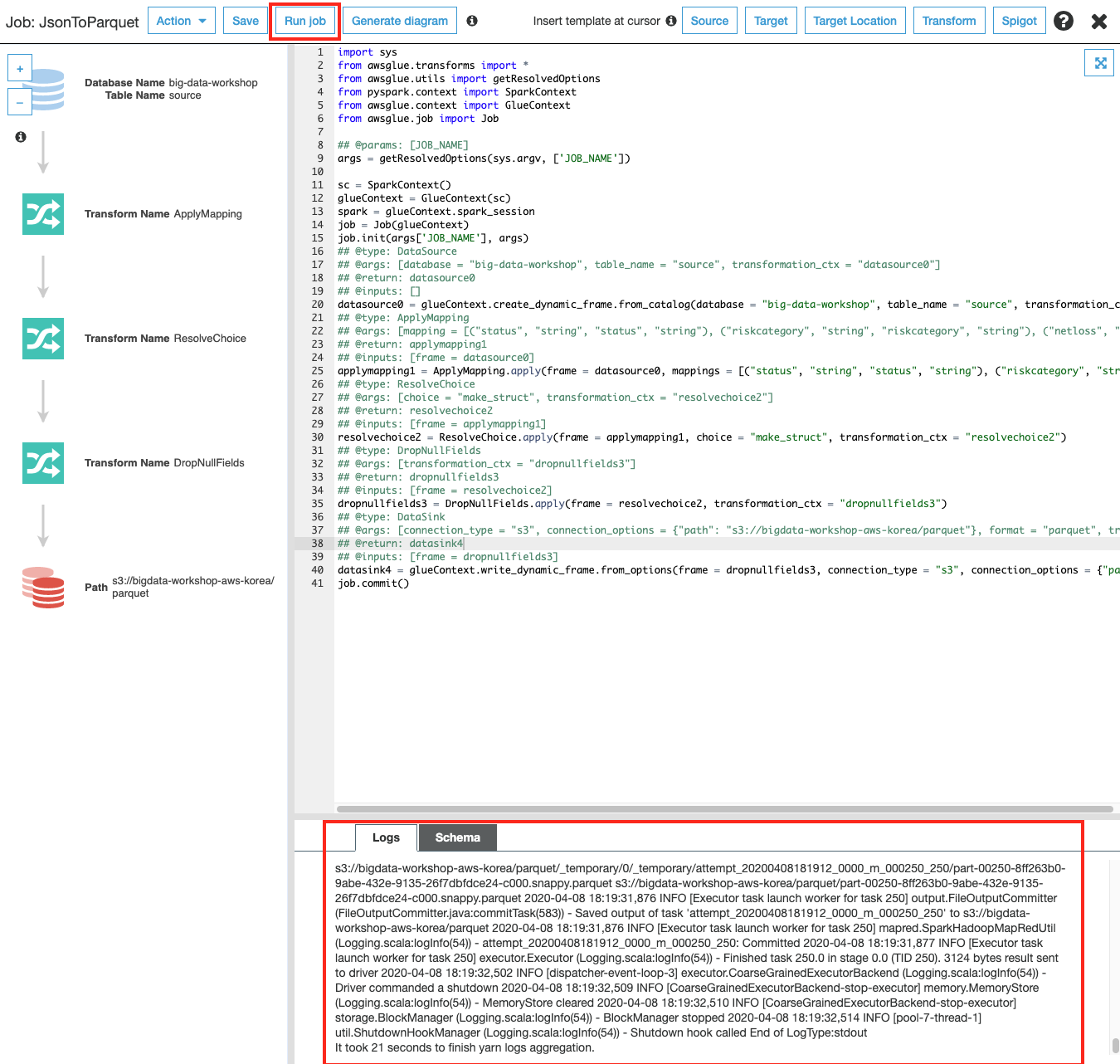
Glue ETL Job이 저장되고 스크립트가 자동으로 생성되고, 수정할 수 있는 화면으로 전환됩니다. 스크립트 내용을 검토한 후 상단의 Run Job 버튼을 클릭하여 ETL을 시작합니다. 작업 완료까지 수 분이 소요될 수 있습니다.
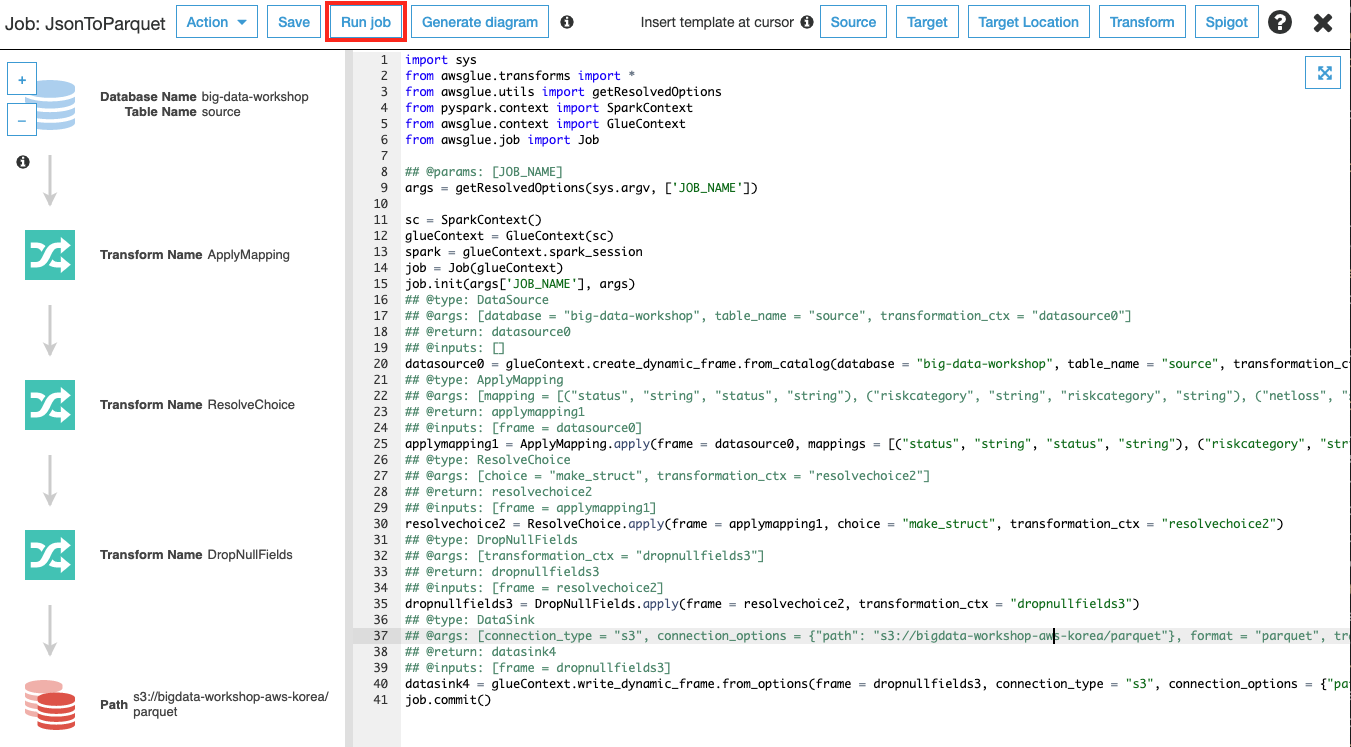 작업을 시작할지 확인하는 창이 나오고, Run job 버튼을 클릭합니다.
작업을 시작할지 확인하는 창이 나오고, Run job 버튼을 클릭합니다.
-
Glue ETL Job이 수행되는 동안 하단 Logs 탭에 수행되는 작업에 대한 로그를 확인할 수 있습니다.
-
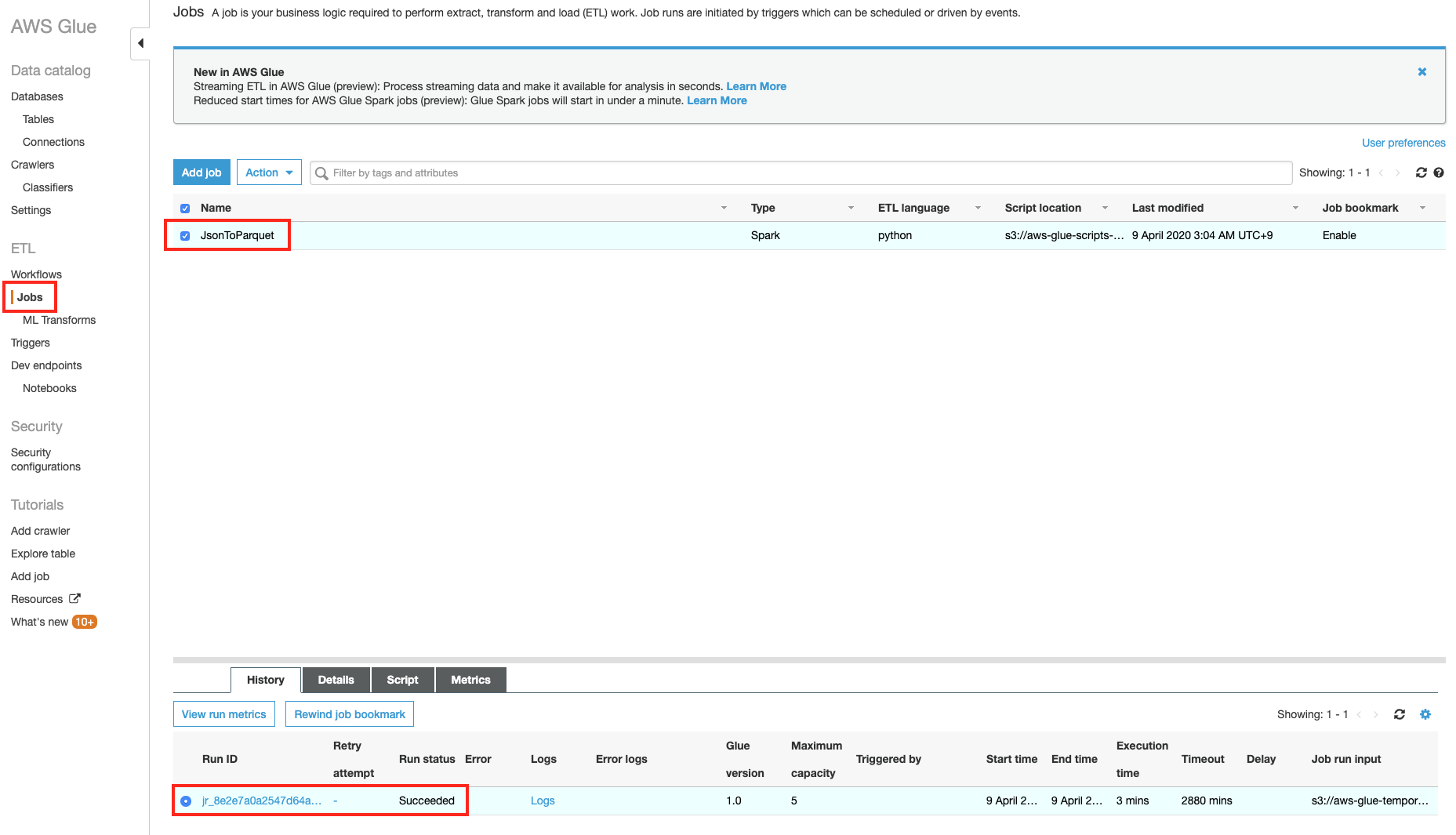
Glue ETL Job이 완료되면, Jobs 메뉴에서 수행한 Job에 대한 이력을 확인할 수 있습니다. 정상적으로 완료되면, Succeded 와 같은 작업 상태와 실행 시간과 같은 이력이 남아 있는 것을 확인할 수 있습니다.
-
수 분이 걸려서 Glue ETL 작업이 끝나면 source에 있던 json 값이 parquet 폴더에 parquet 포맷으로 작업 결과물이 만들어지는 것을 볼 수 있습니다.
S3 버킷의bigdata-workshop-[본인이메일id]/parquet폴더에 parquet 타입 파일이 생성됩니다.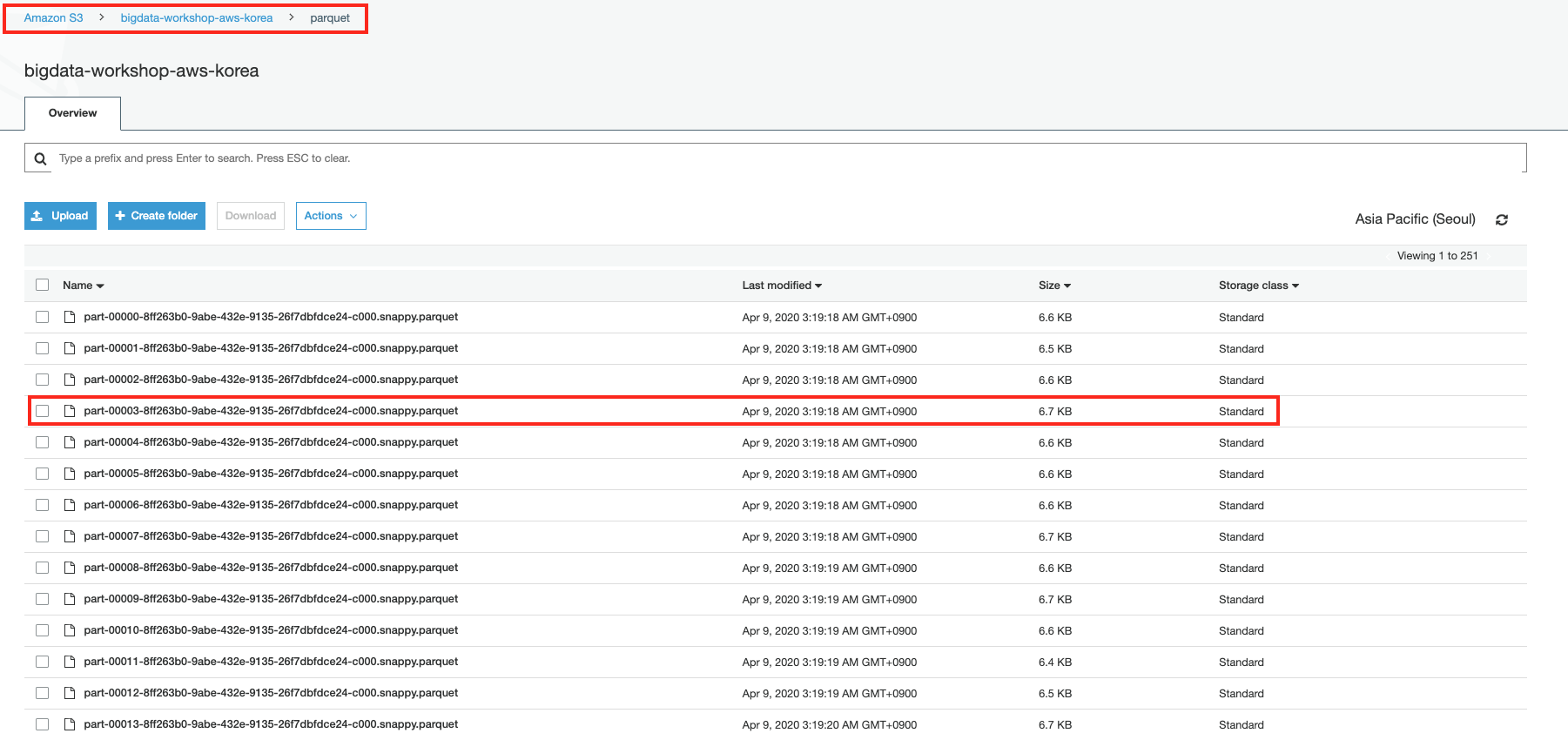
Glue ETL Job 결과 크롤링
Glue ETL이 변환한 Parquet 파일에 대해서 크롤링하여 자동으로 테이블을 생성합니다.
-
Glue의 좌측 메누에서 Crawler 를 클릭하고, 리스트에 있는 big-data-crawler 를 선택하고, Action 버튼을 클릭 후, Edit Crawler 를 선택합니다.
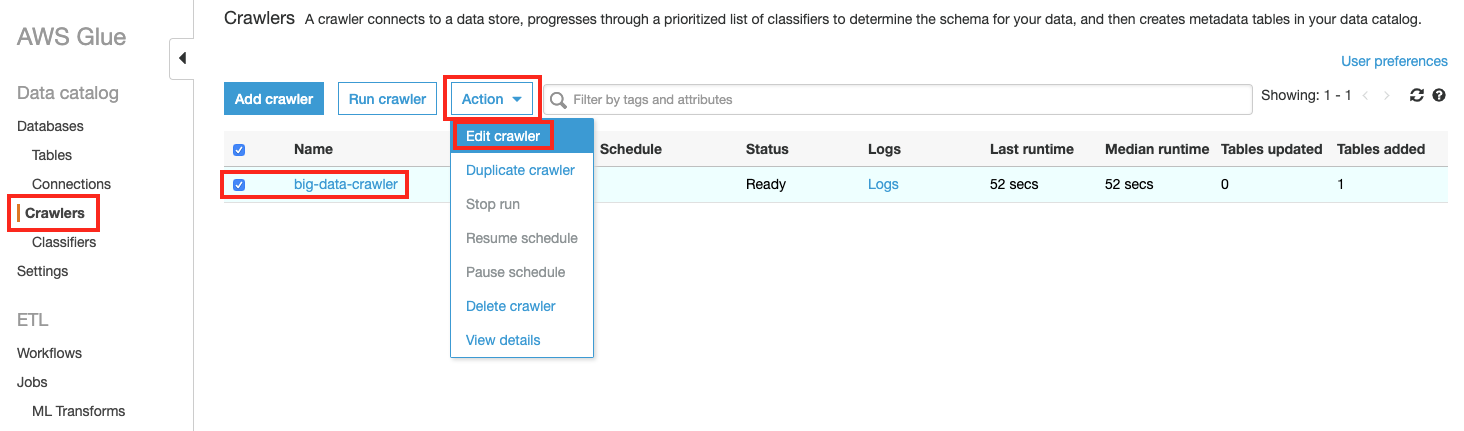
-
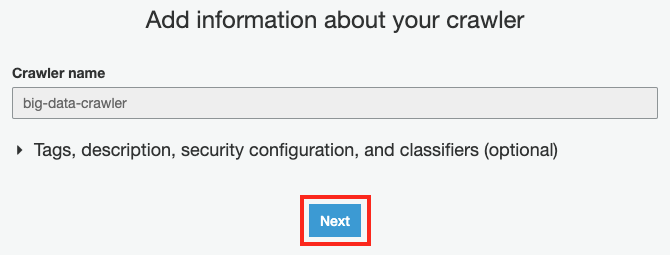
Add information about your crawler 화면에서 Next 버튼을 클릭합니다.
-
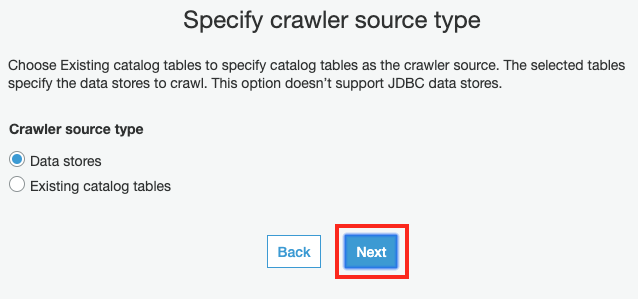
Specify crawler source tpye 화면에서 Next 버튼을 클릭합니다.
-
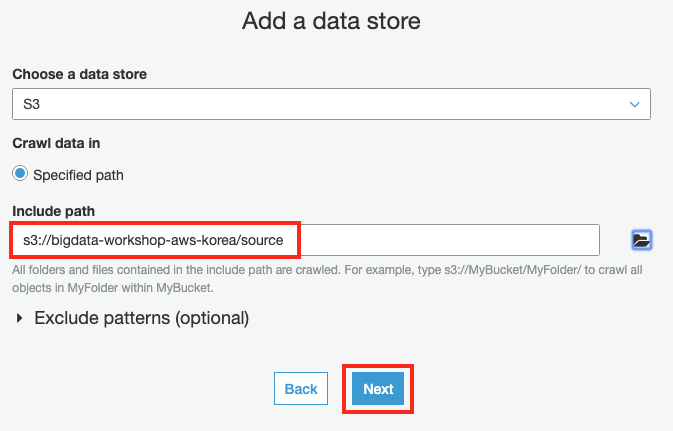
Add a data store 화면에서 기존에 사용했던 source에 대한 설정은 그대로 두고, Next 버튼을 클릭합니다.
-
Add another data store 화면에서 parquet 폴더에 대한 크롤링 작업을 추가할 것이므로, Yes 를 선택하고 Next 버튼을 클릭합니다.
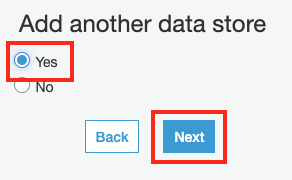
-
Add a data store 화면에서 Include path에
s3://bigdata-workshop-[본인이메일id]/parquet를 입력한 후 Next 버튼을 클릭합니다.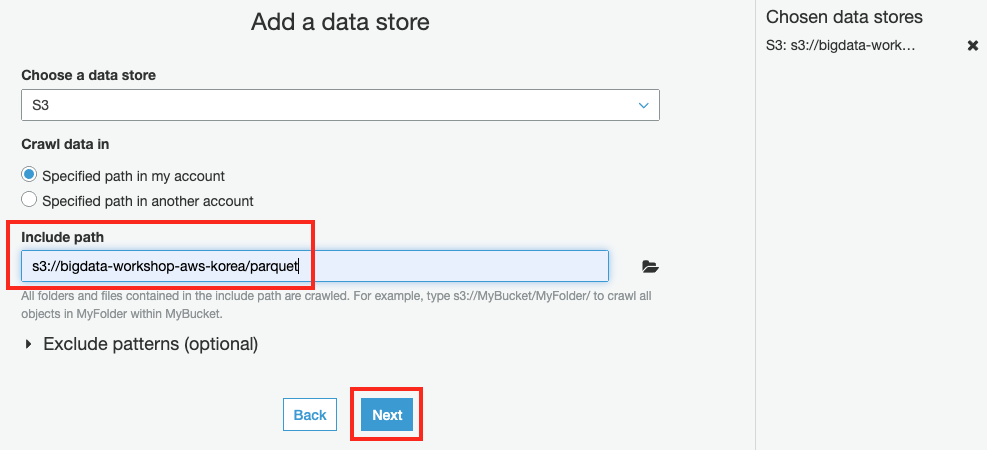
-
Add another data store 화면에서 더 추가할 크롤링 작업이 없으므로, No를 선택하고 Next 버튼을 클릭합니다.
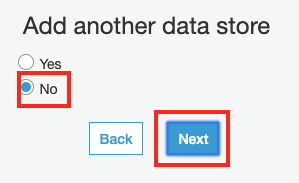
-
Choose an IAM role 화면에서 기존 Role 설정을 그대로 유지한채 Next 버튼을 클릭합니다.

-
Create a schedule for this crawler 화면에서 Next 버튼을 클릭합니다.
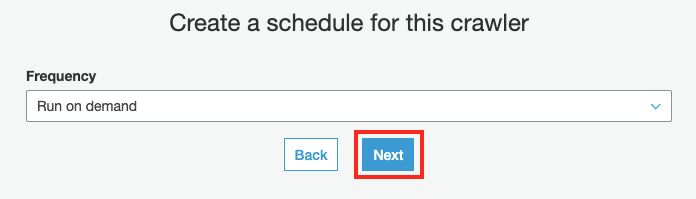
-
Configure the crawler’s output 화면에서 Next 버튼을 클릭합니다.
-
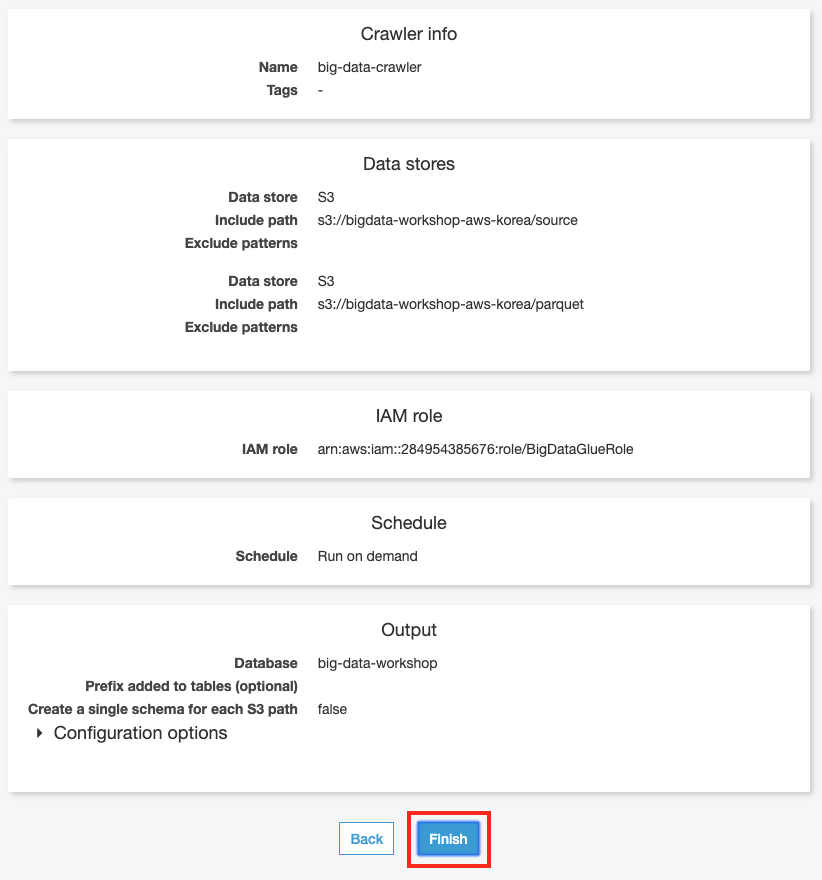
Review 화면에서 Finish 버튼을 클릭합니다.
-
좌측 메뉴의 Crawlers 에 등록된 big-data-crawler 를 리스트에서 선택하고 Run crawler 를 클릭합니다.

-
Crawler 실행이 모두 완료 되면, parquet 테이블 이 생성된 것을 확인할 수 있습니다.
